kafka 概念介绍
kafka 概念介绍

kafka 基础概念
基础概念
- Producer: 消息发送者
- broker: kafka节点
- consumer: 消费者
- topic: 主题,一组消息的集合,分布在多个分区里
- partition:分区, 一个分区只能属于一个主题。在存储曾铭,分区可以看做一个可追加log日志文件,每个消息在分区中表现为一条日志,而消息的位置,通过offset 来记录,offset 是消息在分区分区中的唯一标示,offset保证消息的顺序性,注意,offset 不跨分区,在不同的分区中,offset 可能相同。
- replica:副本,对分区的冗余,会尽量分布在不同的节点。一个分区会有leader 和 follower 两种角色的副本。
- AR(assignded-replica):分区中的所有副本统称为AR
- ISR (in-sync replica):与 leader 副本保持一定程度同步的副本成为 ISR, ISR 是AR 的子集。
- OSR (out-of-sync replica):与leader 同步滞后达到一定程度的副本,这个一定程度可以通过参数进行设置。AR=ISR+OSR
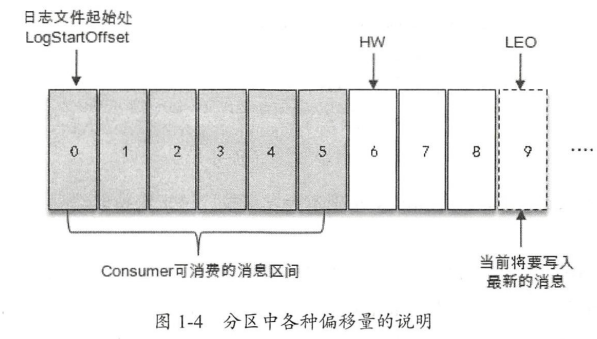
- HW(high watermark 高水位):指一个特殊的OFFSET,消费者,只能获取HW 这个offset 之前的消息,即便HW 之后有其他消息,对消费者而言也是不可见的。(与ISR 强相关)
- LSO(logstartoffset):消息开始的初始offset,值为0
- LEO(logendoffset):当前分区中,下一条待写入消息的offset。
消息处理
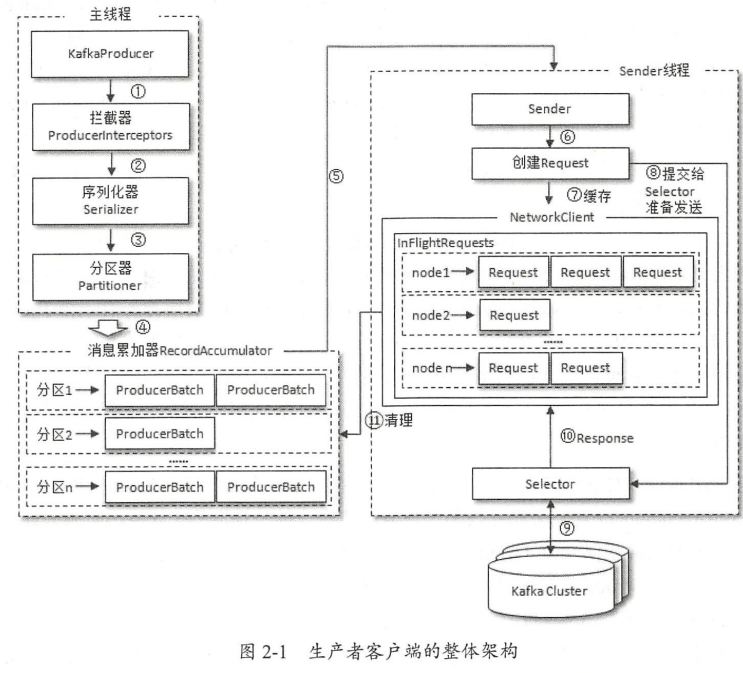
消息的发送过程
producer-> 拦截器(非必须) -> 序列化器 -> 分区器- broker
消息投递方式 P2P , PUB/SUB
kafka 通过消费者组和消费者来适配两种模式
如果所有的消费者头隶属于同一个消费者组,那么消息只会投递给其中一个消费者,相当于P2P模式
如果消费者隶属于不同的消费者组,那么消息会发送给所有的消费者组。适配PUB/SUB模式
消费位移(offset)
指消费者在kafka中的消费位置,注意这个角度跟消息的offset 不是一个意思。消息的offset 是指消息在kafka中的偏移量,而消费位移,是指消费者在分区中将消息消费到了哪一条。消费者在消费完消息之后需要提交消费位移。注意提交的消费位移的值,当前消费过的最后一条消息的offset+1,而不是当前消费了的消息的offset
旧的消费这的消费位移存储在zk中,而新添加的消费这的消费位移存储在kafka的内部主题
_consumer_offsets中
消费位移的提交
kafka 默认是自动提交(客户端参数,enable.auto.commit),然后自动提交容易造成消息丢失。消费位移的提交并不是每消费一条消息就提交,而是定期提交,通过参数(auto.commit.interval.ms) 指定提交间隔。默认是5秒
再均衡
只一个一个分区的的所有权,从一个消费者分配給另一个消费者的过程。再均衡存在以下影响
- 再均衡期间,消费组不可用。
- 可能存在重复消费。例如一个消费者A消费完后,还没来得及提交消费位移,就发生了再均衡。而消费者A被分配到了另一个分区。
- 再均衡时,可以通过subscribe()方法中的,均衡监听器,进行处理。
- onPartionRevoked 方法,这个方法在再均衡发生之前,和消费者停止读取消息之后被调用。可以用来处理提交消费位移。避免不必要的重复消费。
主题的创建
| 创建方法 | 相关参数 | 参数说明 |
|---|---|---|
| 自动创建 | auto.create.topics.enable (default=true) | 如果topic不存在,则自动创建 |
| 自动创建 | default.replica.factor(default=1) | 自动创建topic的副本数 |
| 自动创建 | num.partitions | 自动创建topic的分区数 |
| 手动方式 | kafka-topic.sh 默认工具 | kafka-topic.sh –zookeeper localhost:2181/kafka –create –topic test –partitions 4 –replica-factor 2 |
分区管理
分区副本的分配
在创建主题时,如果使用了repilica-assignment参数,就按照指定方案进行分配。如果没有指定,使用默认的方案进行分配。
默认分配方案(kafka-topic.sh 脚本命令创建)
- 未设置机架分配方案,当所有broker都未设置broker-rack,或者使用disable-rack-aware 参数创建时。
分区修改
分区只能增加不能缩减。
理由,得不偿失,1 需要考虑删除分区消息如何处理,如果复制到剩下的分区,资源站用太大。3 对于spark flink 此类组件,需要时间戳。消息的时间戳如何保存?
优先副本
在分区的副本中,处于第一位置的副本被称为优先副本,优先副本在leader 宕机时,会优先被选举为新的leader

自动平衡
auto.leader.rebalance.enable,默认为true,生产环境推荐设置为false。再平衡会影响可用性。当设置为true时,kafka会有一个定时任务,(默认是5分钟通过 leader.imbalacne.check.interval.seconds设置)定时检查集群的不平衡率,如果不平衡率超过leader.imbalance.per.broker.percentege参数的值(默认10%),就执行自动平衡。
不平衡率
不平衡率=非优先副本的leader个数/分区总数
分区重分配
解决的问题
当删除节点时,期望将该节点上的分区副本迁移到其他节点上。
当添加节点时,期望能够将已经创建的主题的负载均匀地分配到新节点中。
kakfa通过 kafka-reassign-partitions.sh 脚本来实现重分配,主要氛围三步。
- 创建一个包含主题清单的json文件
- 根据主题清单和broker节点生成重新分配方案
- 执行方案
json文件格式如下
{
"topics":[
{"topic":"topic1"}
],
"version":1
}
运行
kafka-reassign-partitions.sh --zookeeper localhost:2181/kafka --generate --topic-to-move-json move.json --broker-list 0,2
运行后将会打印 current partition replica assignment,与 proposal partition reassginment configuration。 两个都是json格式,显示在控制台
proposal 的json 内容保存为一个接送文档,proposal.json
运行
kafka-reassgin-partitions.sh --zookeeper localhost:2181/kafka --execute --reassignement-json-file proposal.json
复制限流
在borker级别,通过如下两个参数来进行限流
- follower.replication.throttled.rate
- leader.replication.throttled.rate
follower.replication.throttled.rate表示follower副本复制的速度,leader.replication.throttled.rate设置leader副本传输速度, 单位都为B/s 通常情况下,两者设置相同。
在topic 级别,通过如下两个参数来进行下限流
- follower.replication.throttled.rate
- leader.replication.throttled.rate
follower.replication.throttled.rate表示follower副本复制的速度,leader.replication.throttled.rate设置leader副本传输速度, 单位都为B/s 通常情况下,两者设置相同。
四个参数都通过kafka-config.sh 命令来配置,以broker级别为例
kafka-config.sh --zookeeper localhost:2181/kafka --entity-type brokers/topics --entity-name 1 --alter --add-config follower.replication.throttled.rate=1024,leader.replication.throttled.rate=1024
如何选择合适的分区数
kafka分区,受linux 文件描述符上限的限制。
日志存储
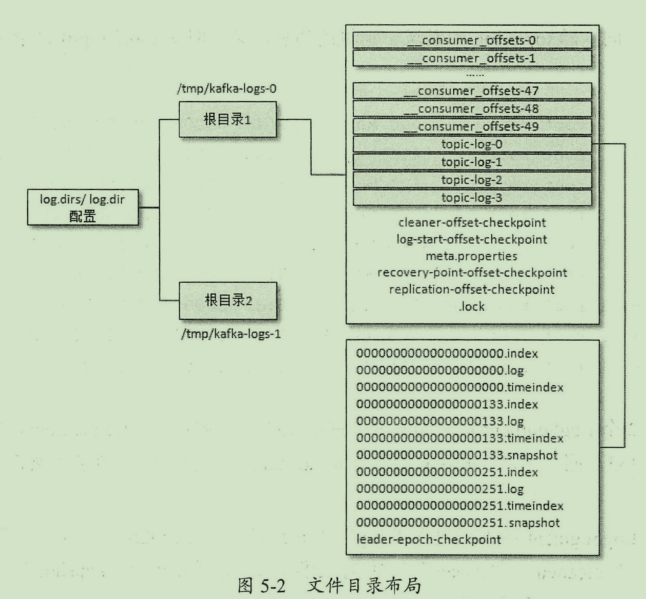
目录结构
一个有四个分区的主题会在kafkalog 文件夹下生成四个文件夹,分别以
一个分区对应一个log,在log文件夹中,日志文件被分成多个 log segment, 表示一个大log中的一小段。
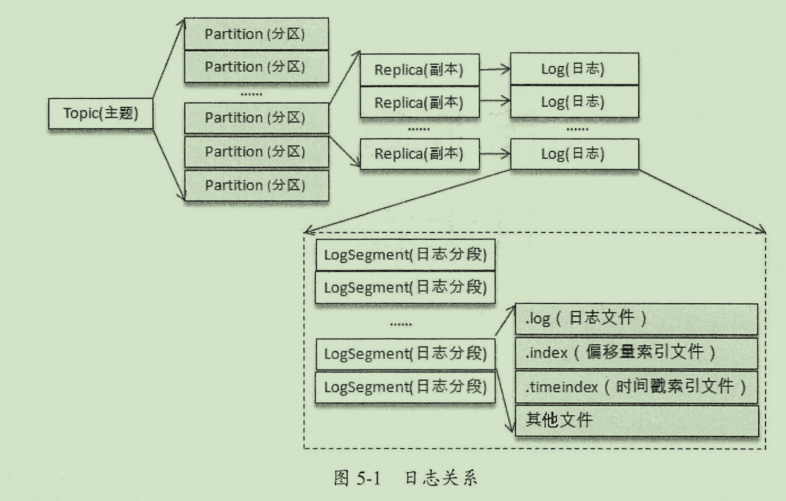
日志文件
00000000000000000000.log
00000000000000000251.log
日志索引
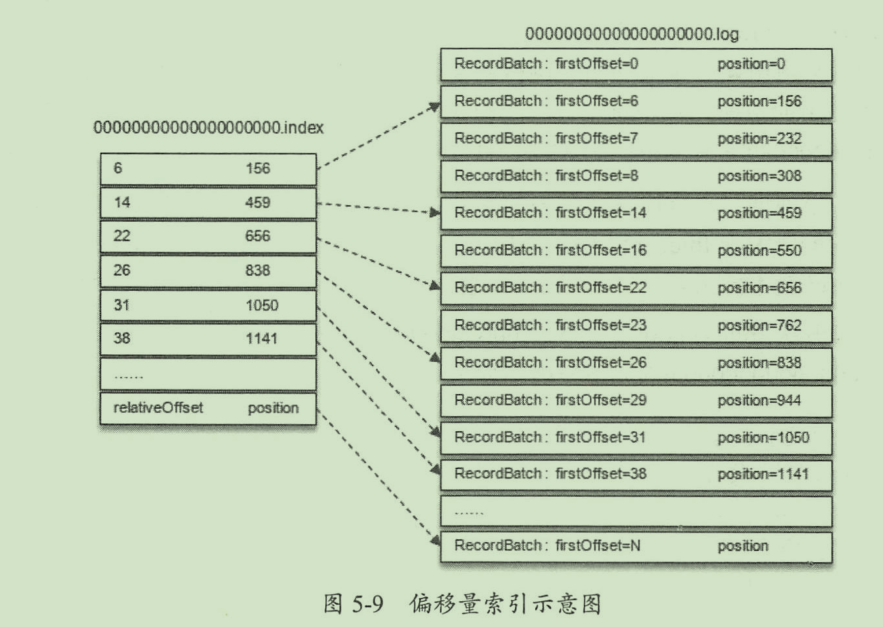
kafka 索引文件是稀疏索引,并不是每条消息都对应一条索引记录。而是每当写入一定量的消息(具体大小由log.index.interval.bytes指定,默认4096,即4KB)时,偏移量索引文件.index 和时间戳索引文件.timeindex 分别增加一条索引记录。log.index.interval.bytes的值将影响索引文件的索引密度。偏移量索引文件的索引是单调递增的。所以稀疏索引的查找使用的是二分查找法。
索引文件的拆分的触发条件
- 当索引文件大小大于log.segments.bytes时,被自动分段
- 当日志文件的最大时间戳与系统当前的时间差值大于log.roll.ms 或大于log.roll.hours时,进行拆分,如果同时配置了两个参数,那么log.roll.ms 优先级高。
- 偏移量索引文件或者时间索引文件的大小超过log.index.size.max的值。
- 追加消息的偏移量,与当前日志的偏移量之间的差值大于Integer.maxvalue
偏移量索引
偏移量索引结构

偏移量索引与日志的对应关系
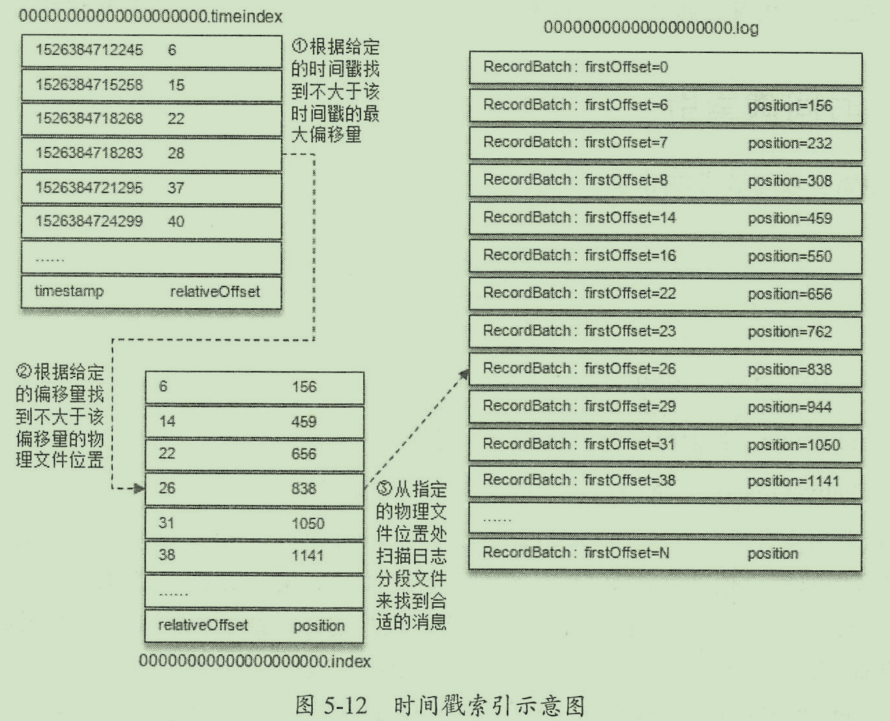
时间戳索引
格式
timestamp+relativeOffset
timestamp 当前日志分段最大时间戳
relativeOffset 时间戳所对应的消息的相对偏移量
日志删除
基于时间,默认7天
基于日志大小,超过阈值的部分,会将日志的分段文件删除一部分,默认删除旧数据
基于起始偏移量。
日志压缩
磁盘存储
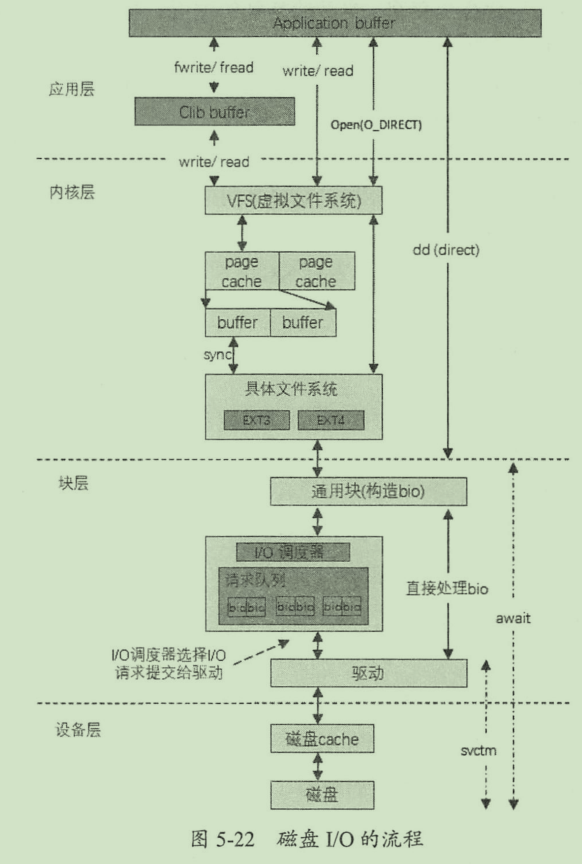
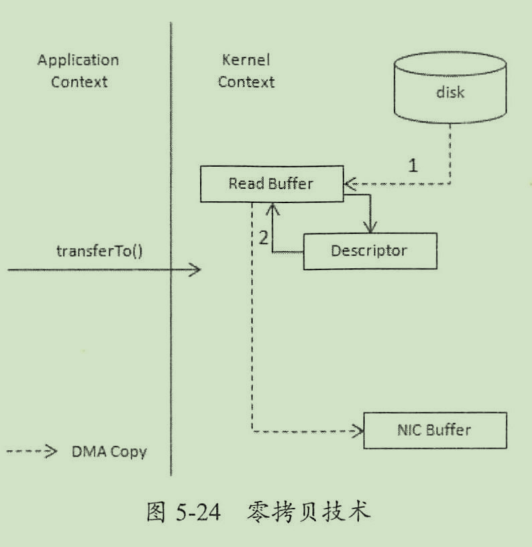
零拷贝
指直接将数据从磁盘拷贝到网卡设备。底层依赖于linux系统的sendfile()实现,对应java的filechannel.transferto
非零拷贝的四次复制过程
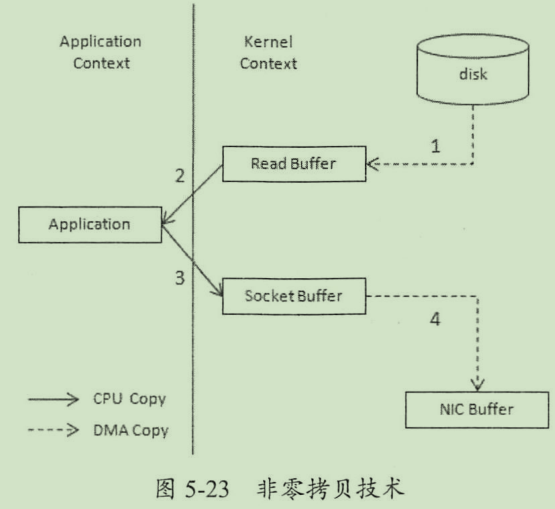
零拷贝复制