kafka 深入理解
kafka 深入理解

kafka 服务端
协议
在2.0版本中支持43中协议,每种协议包含相同的请求头和不同的请求体。
请求头
请求头包含四个字段
| 字段 | 说明 |
|---|---|
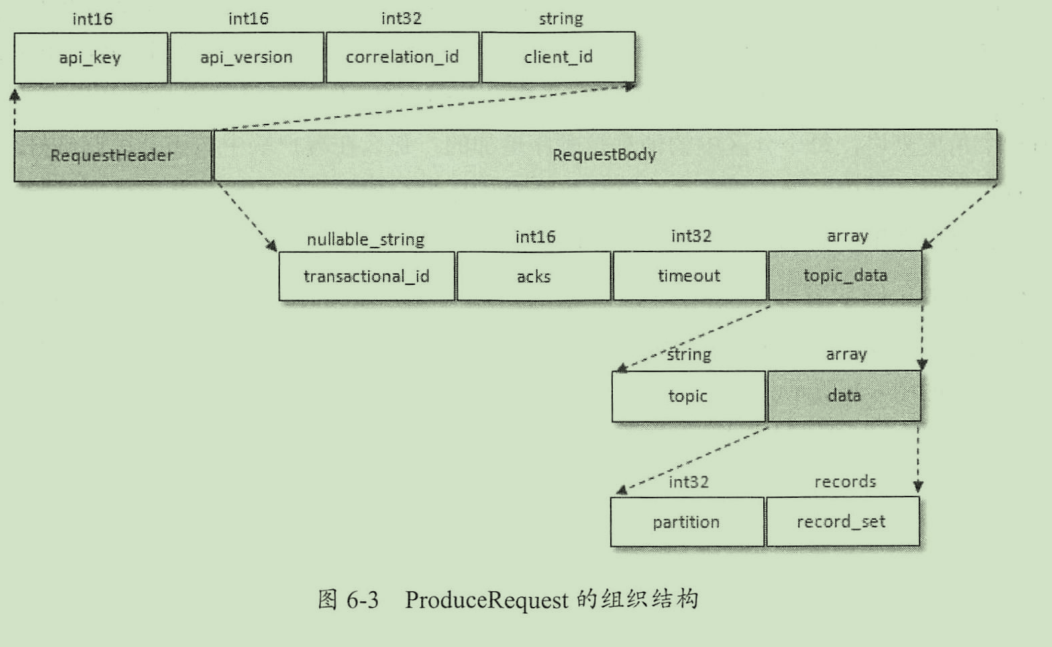
| api_key | api标识 比如 produce fetch等。说明需要执行的动作 |
| api_version | api 版本号 |
| corelation_id | 由客户端生成的请求id(全局唯一),服务端(broker)在处理完请求后也会把相同的id写回 |
| client_id | 客户端id |
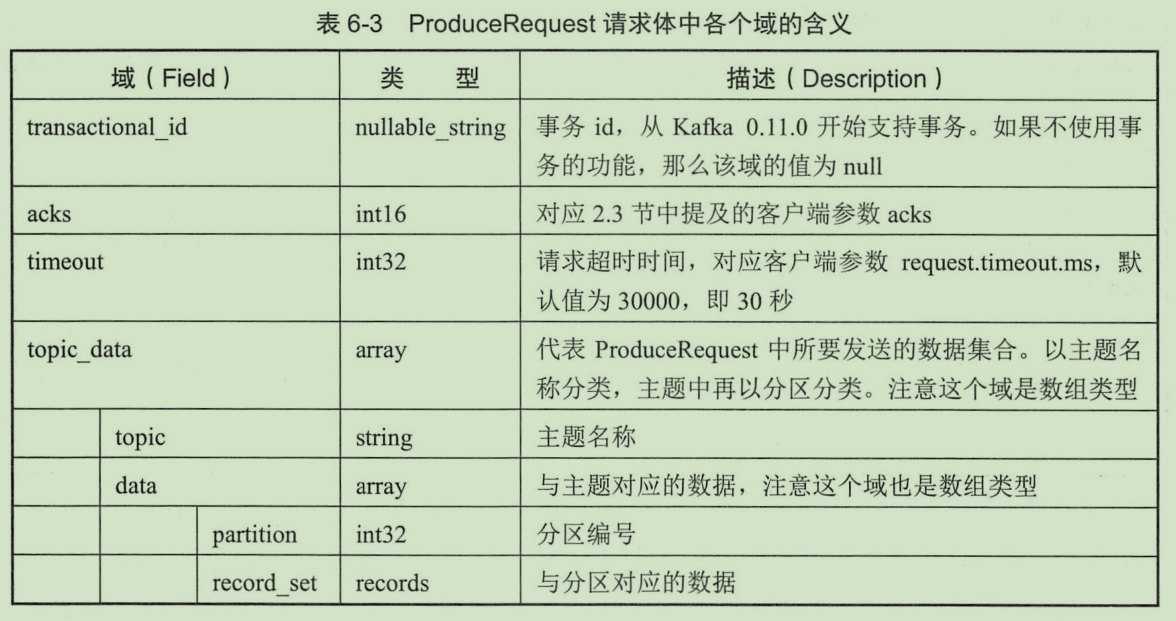
produce request 结构
消息处理过程
sender线程从消息累加器中获取消息
如果acks 的值为非0,客户端将异步等待服务端的相应(ProduceResponse)
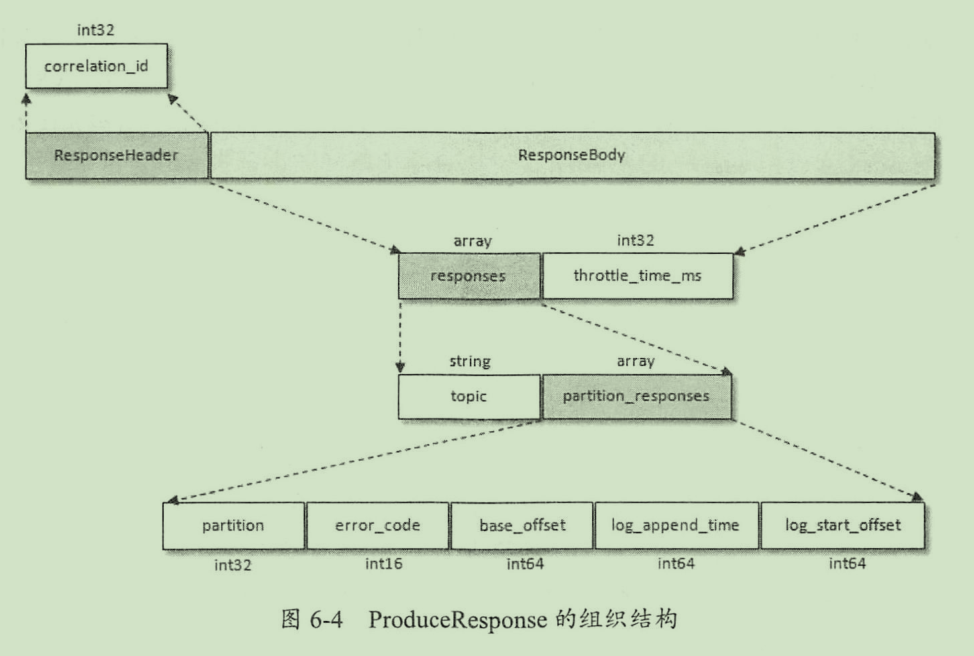
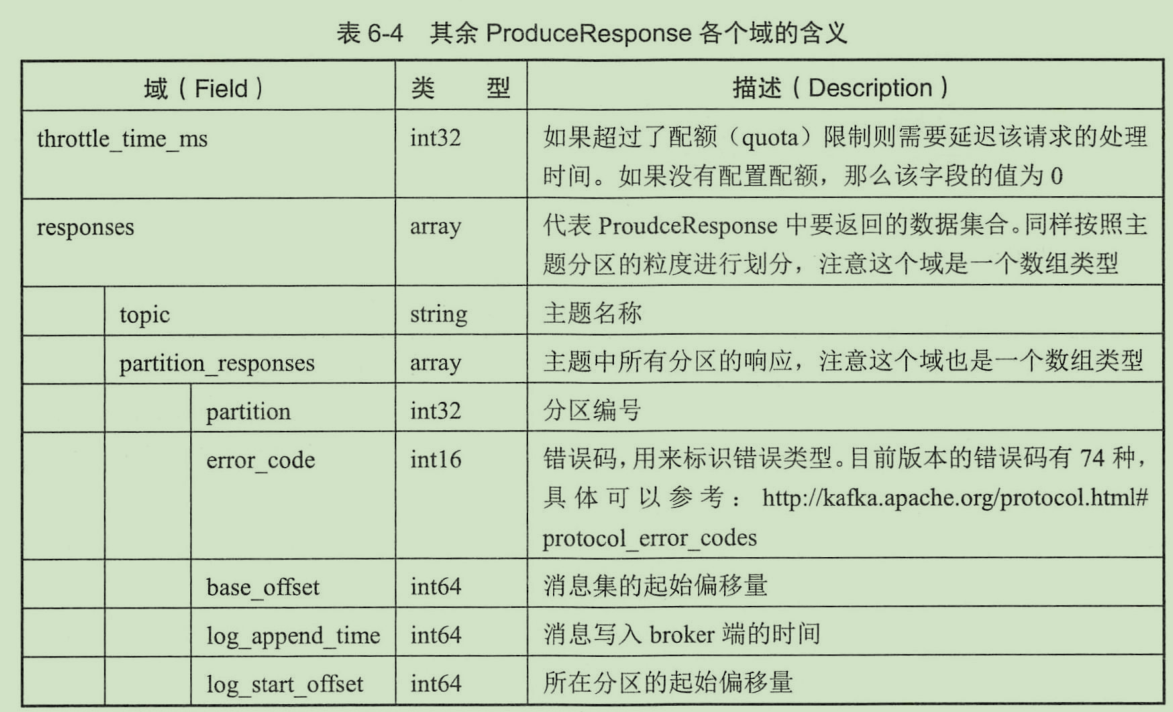
produce response 结构
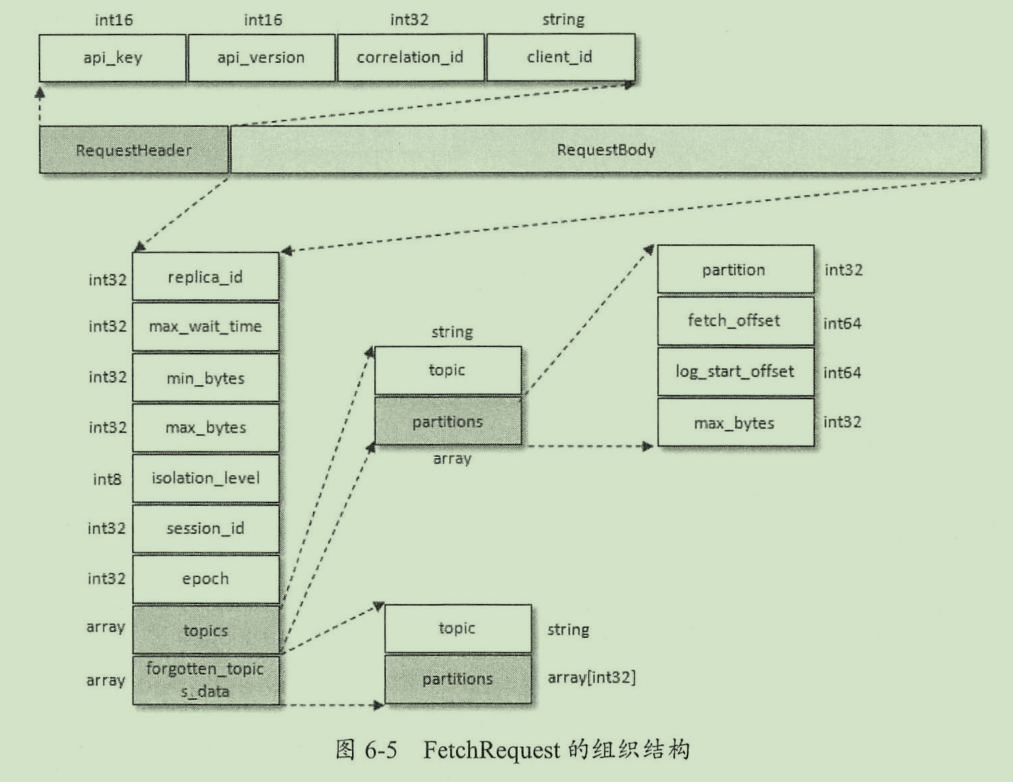
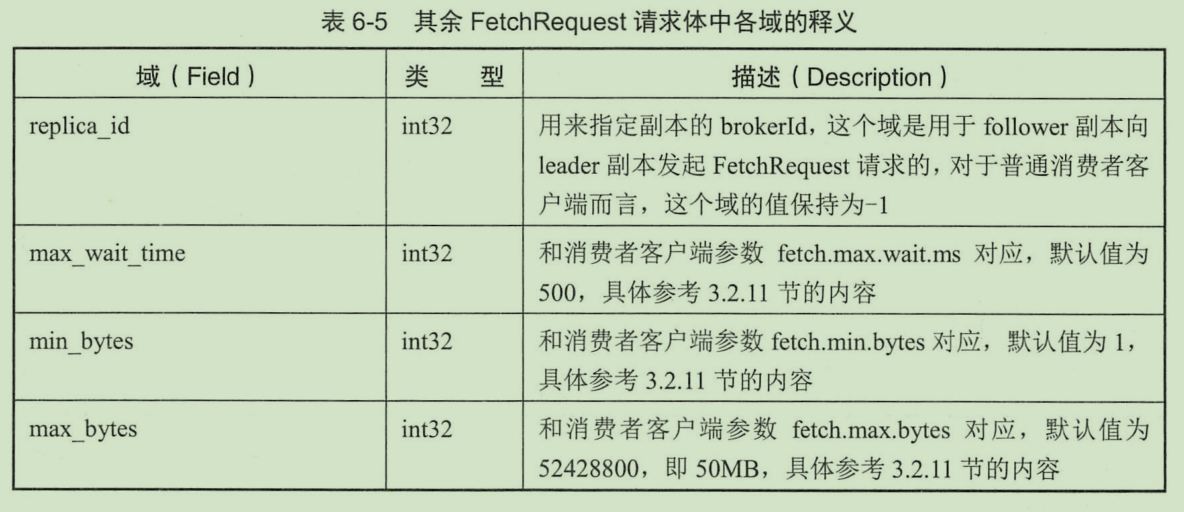
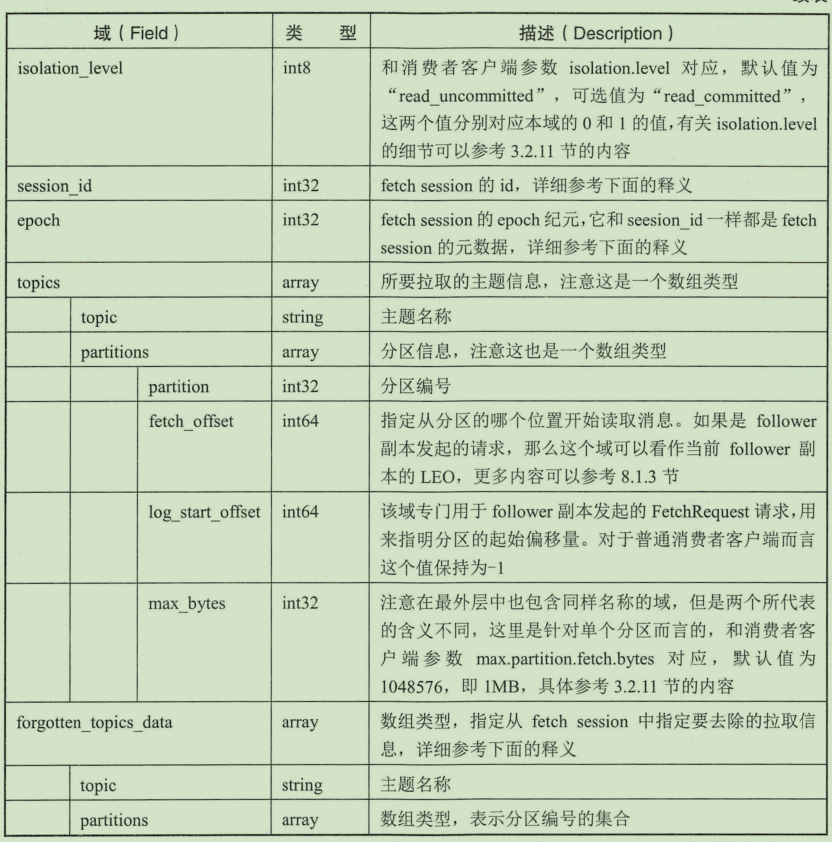
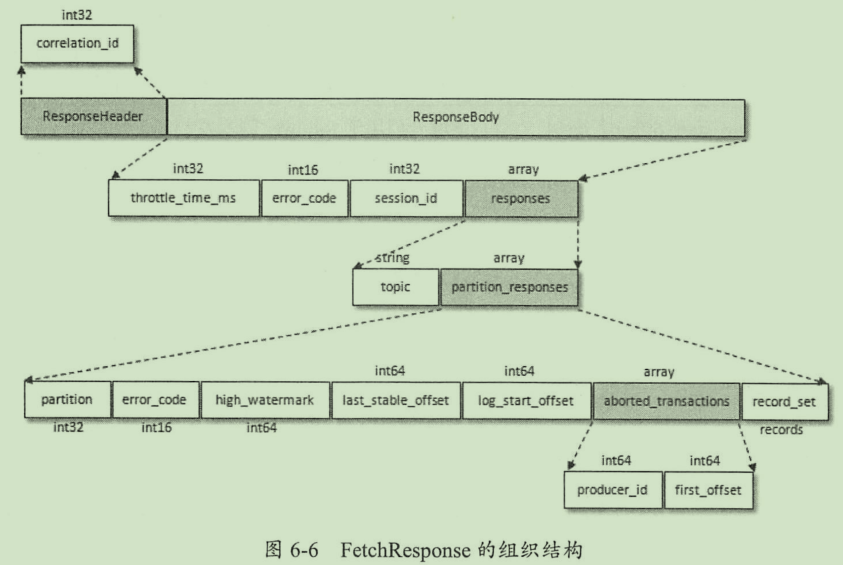
Fetch 请求/响应的结构
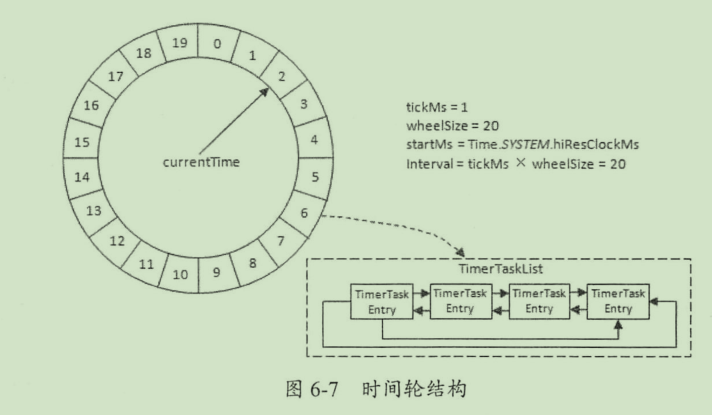
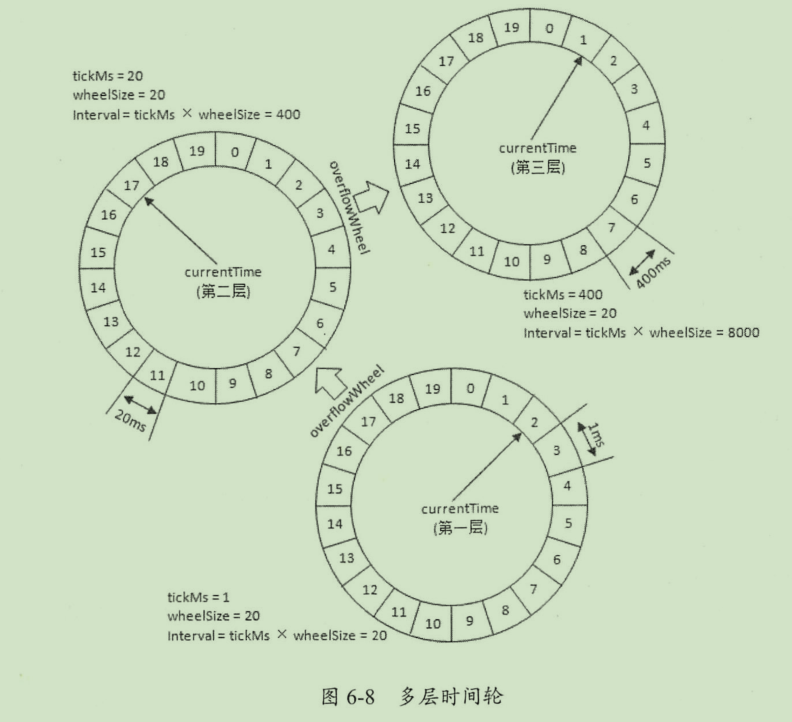
时间轮(timingwheel)
时间轮是一个存储定时任务的环形队列,底层采用数组实现。数组中的每个元素存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个双向链表,链表中的每个元素表示一个任务项(TimerTaskEntry)封装了真正的任务(TimerTask)
相关概念
- tickms 基本时间跨度
- wheelSize 时间格数
- interval 总体时间跨度 = tickms x wheelSize
- 层级,时间轮是分层级的,每一层的时间格数不变,但是上一层的基本时间跨度=下一层的总时间跨度
延迟操作
当acks设置为-1时,会生成一个延时操作,只有消息同步到所有分区后才发送返回。
控制器
选举
控制器的选举,通过向zookeeper 中创建/controller 临时节点来进行竞争。成功创建的节点即为控制器。
/controller 中包含三个变量
- version 固定为1
- broker_id 成功竞选为控制器的broker的id
- timestamp 竞选成功的时间
/controller_epoch 记录控制器变化的次数。
控制器的职责
- 监听分区变化,通过在zookeeper中注册相关的handler来实现
- 监听主题变化,通过在zookeeper中注册相关的handler来实现
- 监听broker变化,在zookeeper中/brokers/ids节点添加BrokerChangehandler 实现
- 读取集群相关信息进行管理
- 启动并管理分区状态机与分区状态机
- 更新集群元数据
关闭流程
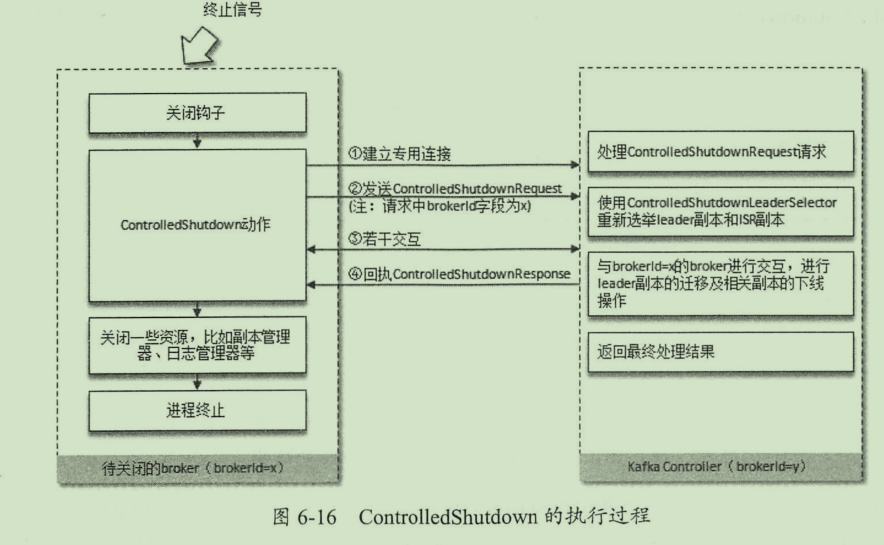
分区leader 选举
分区的选举由控制器实施,策略为OfflinePartitionLeaderElectionStrategy,选取AR 中,第一个存活的副本。
客户端
分区分配策略
分区策略通过 partition.assignment.strategy 指定,可用的策略有三种
- rangeAssignor
- RoundRobbinAssignor
- StickyAssignor
rangeAssignor
n=分区数/消费数,m=分区数%消费数。 前m个消费者分配n+1个分区,剩下的消费者分配n个分区
RoundRobbinAssignor
将消费组内的消费者和消费者所订阅的主题的分区,按字典表排序,然后依次分配个消费者。
StickyAssignor
目标
分区尽可能均匀
分区尽可能与上次分配一致。
当两者发生冲突时,优先保证第一目标。
消费者协调器和组协调器
消费者协调器用来协调当单个消费者指定了多个分区分配策略时,策略的优先级,或者不同消费者之间,使用了不同的分区分配策略时的分区分配。
再均衡的原理
再均衡的实现,通过客户端的ConsumerCoordinator 与 服务端的 GroupCoordinator 交互实现。 消费者组在客户端被分成了子集,每个子集有一个服务端的GroupCoordinator与之对应 。
再均衡的触发条件
- 有新的消费者加入
- 长时间为得到某个消费者的心跳。
- 消费者发送LeaveGroupRequest 请求,退出消费组
- 消费组所对应的GroupCoordinator节点发生变更
- 消费组内定于的主题,或者主题的分区数发生变化
再均衡的四个阶段
find Coordinator 消费者与GroupCoordinator 建立连接,如果消费者保存了GroupCoordinator 的信息就直接发起连接,如果没有就像集群中最小负载的 broker 发起查询请求,然后再简历连接。
join group,建立GroupCoordinator 的连接后,消费者发起加入group 的请求,并处理返回的消息。其中memberid是groupCoordinator分配给消费者的ID。group_protocals 与消费者配置的partitions.assignment.strategy 参数相关,如果配置了多个就会包含多个protocol_name 和 protocol_metadata。如果消费者是重新加入,那么在发送joinGroupRequest之前,需进行如下额外动作
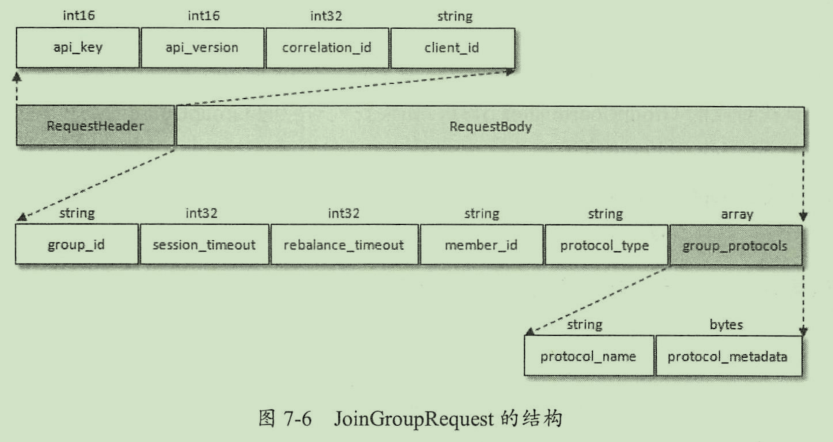
- 如果消费者是重新加入切enable.auto.commit=true,那么在发送joinGroupRequest之前,需要想GroupCoordinator提交位移,这个过程是阻塞的,要么成功,要么超时。
- 如果消费者注册了自定义再分配监听器,那么在加入消费组之前,会执行自定义监听器的逻辑。
- 禁用与GroupCoordinator之间的心跳检测。
然后选举消费组的leader,如果消费组内没有leader 则第一个加入的消费者为leader,如果leader 退出消费组,则随机再选一个。
各个消费者将自己所支持的分区分配策略组成candidate数组,然后为candidate中的策略投票,投票规则为,如果是自己所支持的策略,就投一票。得票最多的策略胜出。如果胜出的策略有消费者不支持,那么将报出异常。
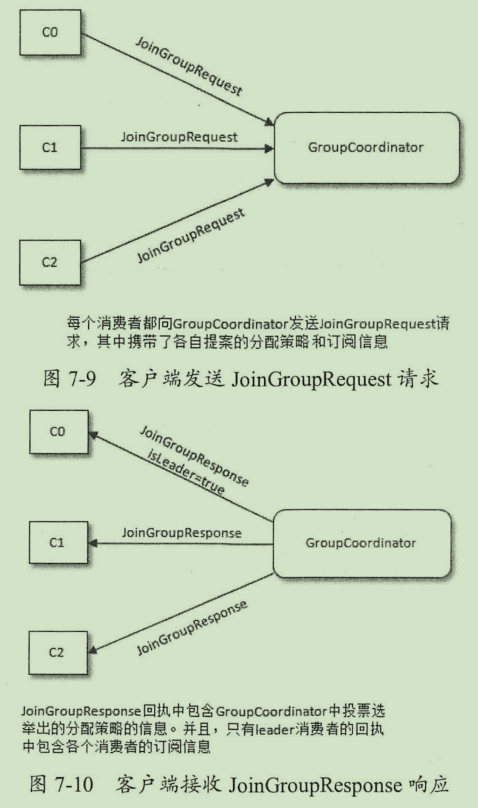
选举消费组的leader,通过GroupCoordinator,将选出的分区分配策略同步给其他的member
消费者向 GroupCoordinator 发送心跳,开始正常工作。
事务
消息传输保障
- 最多一次,消息可能会丢,但不会重复
- 最少一次,消息不会丢,但可能重复
- 有且只有一次,消息保证一定送达,且只送达一次。
幂等性
幂等性参数需要生产端开启enable.idempotence=true,这个参数开启后,会对另外三个参数进行限制性要求。
- retries >0 default=Integer.Max_value
- acks = -1 default = -1
- max.in.flight.requests.per.connection <= 5 default =5
kafka 通过生产者id(PID)+分区号+序列号 标识一条唯一的消息。序列号单调递增。相当于kafka 维护了一个以PID+分区号为 key 以序列号为value的map,。序列号从0开始,生产者每发送一次消息,就将对应key中的序列号加1,broker 同时也维护了一份 key value map ,指由当新到达消息的序列号,为当前序列号+1时,才接收消息,否则拒绝消息,抛出异常。如果新到达的消息的序列号> 大于当前消息+1 说明中间有消息漏掉了。同样会抛出异常。
事务
幂等性不能夸分区,事务可以包整多个分区写入消费的原子性。
启用事务需要在客户端设置transactionid,同时需要启用幂等性enable.idempotence=true,一个transcationid 只能开启一个生产者,kafka在消费者端,对事务的语义偏弱,没法得到完全的保障。
消费者端 isolation.level 参数对事务的可见性如下
- 设置为 read_uncommit 可以看到未提交的事务与已提交的事务
- 设置为 read_commit 可以看到已提交的事务。
可靠性
判断follower失效。
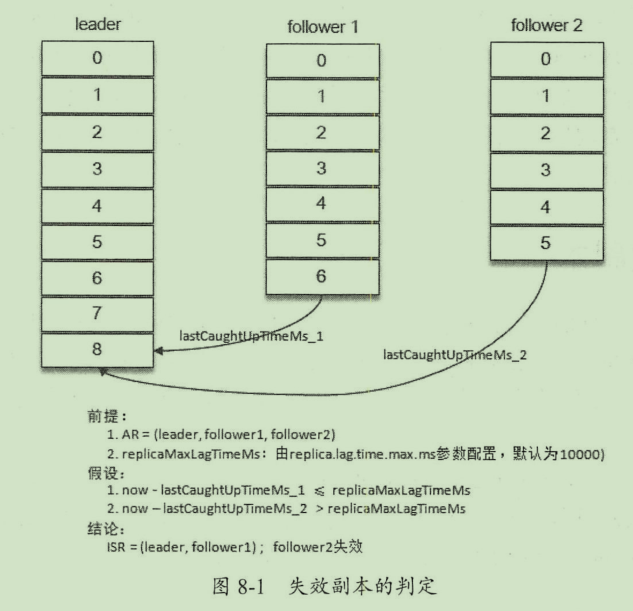
当follower的同步记录追赶上leader的LEO, 此时更新follower的lastCaughtUpTimeMs,kafka的副本管理器会定期检测follower的lastCaughtUpTimeMs 与当前时间的差值,如果小于replica.lag.time.max.ms 就会将follower 重新加入ISR中。
ISR 伸缩
kafka启动后有两个ISR 检测的定时任务,isr-expiration 与 isr-change-propagation。 如果检测到某个副本失效,则会将变更后的记录写到zookeeper的/broker/topics/
- 上次的isr变更信息与现在的时间差>5s
- 上次写入zookeeper的时间与现在的时间差> 60s
LastEndOffset (leo)(副本的总offset) 与 High-Watermark(可读取消息的上线offset) , Low-wartermark(可读取分区的下线offset)
leo>hw>lw
日志同步机制
kafka 动态维护一个 ISR,只有当ISR 当中所有的节点都复制完消息之后,消息才会被认为是提交成功。这个方案的有点是要容忍 x 个节点失效,只需要 x+1 个节点的副本。缺点是,需要等待最慢副本也同步完成才能认为是消息确认。
可靠性分析
可靠新相关参数
- ack 值为1时 leader 接收消息即为确认,为0 时生产者发送完消息就确认,为-1时所有 follower 同步完消息才算确认
- retries 值不能大于5。retry 可能引起消息乱序,如果要保障顺序,需要max.in.flight.requests.per.connection =1,然后为1 会影响并发度。
- retry.backoff.ms 重试的间隔时间
- min.insync.replicas 最小保障的ISR 副本数,如果可用的ISR 数比这个数字少,连接时会报出异常。
- unclean.leader.election.enble, 是否允许非ISR 选举为leader
考题
声明
本文问题参考朱小厮的博客。写这个只是为了检验自己最近的学习成果,因为是自己的理解,如果问题,欢迎指出。废话少说,上干货。
正文
1. Kafka的用途有哪些?使用场景如何?
总结下来就几个字:异步处理、日常系统解耦、削峰、提速、广播
如果再说具体一点例如:消息,网站活动追踪,监测指标,日志聚合,流处理,事件采集,提交日志等
2. Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
ISR:In-Sync Replicas 副本同步队列
AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度, 当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
3. Kafka中的HW、LEO、LSO、LW等分别代表什么?
HW:High Watermark 高水位,取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置上一条信息。
LEO:LogEndOffset 当前日志文件中下一条待写信息的offset
HW/LEO这两个都是指最后一条的下一条的位置而不是指最后一条的位置。
LSO:Last Stable Offset 对未完成的事务而言,LSO 的值等于事务中第一条消息的位置(firstUnstableOffset),对已完成的事务而言,它的值同 HW 相同
LW:Low Watermark 低水位, 代表 AR 集合中最小的 logStartOffset 值
4. Kafka中是怎么体现消息顺序性的?
kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。 整个topic不保证有序。如果为了保证topic整个有序,那么将partition调整为1.
5. Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
拦截器->序列化器->分区器
6. Kafka生产者客户端的整体结构是什么样子的?
7. Kafka生产者客户端中使用了几个线程来处理?分别是什么?
2个,主线程和Sender线程。主线程负责创建消息,然后通过分区器、序列化器、拦截器作用之后缓存到累加器RecordAccumulator中。Sender线程负责将RecordAccumulator中消息发送到kafka中.
9. Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
10. “消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?
不正确,通过自定义分区分配策略,可以将一个consumer指定消费所有partition。
11. 消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
offset+1
12. 有哪些情形会造成重复消费?
消费者消费后没有commit offset(程序崩溃/强行kill/消费耗时/自动提交偏移情况下unscrible)
13. 那些情景下会造成消息漏消费?
消费者没有处理完消息 提交offset(自动提交偏移 未处理情况下程序异常结束)
14. KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
1.在每个线程中新建一个KafkaConsumer
2.单线程创建KafkaConsumer,多个处理线程处理消息(难点在于是否要考虑消息顺序性,offset的提交方式)
15. 简述消费者与消费组之间的关系
消费者从属与消费组,消费偏移以消费组为单位。每个消费组可以独立消费主题的所有数据,同一消费组内消费者共同消费主题数据,每个分区只能被同一消费组内一个消费者消费。
16. 当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
创建:在zk上/brokers/topics/下节点 kafkabroker会监听节点变化创建主题 删除:调用脚本删除topic会在zk上将topic设置待删除标志,kafka后台有定时的线程会扫描所有需要删除的topic进行删除
17. topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以
18. topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不可以
19. 创建topic时如何选择合适的分区数?
根据集群的机器数量和需要的吞吐量来决定适合的分区数
20. Kafka目前有那些内部topic,它们都有什么特征?各自的作用又是什么?
__consumer_offsets 以下划线开头,保存消费组的偏移
21. 优先副本是什么?它有什么特殊的作用?
优先副本 会是默认的leader副本 发生leader变化时重选举会优先选择优先副本作为leader
22. Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理
创建主题时 如果不手动指定分配方式 有两种分配方式
消费组内分配
23. 简述Kafka的日志目录结构
每个partition一个文件夹,包含四类文件.index .log .timeindex leader-epoch-checkpoint .index .log .timeindex 三个文件成对出现 前缀为上一个segment的最后一个消息的偏移 log文件中保存了所有的消息 index文件中保存了稀疏的相对偏移的索引 timeindex保存的则是时间索引 leader-epoch-checkpoint中保存了每一任leader开始写入消息时的offset 会定时更新 follower被选为leader时会根据这个确定哪些消息可用
24. Kafka中有那些索引文件?
如上
25. 如果我指定了一个offset,Kafka怎么查找到对应的消息?
1.通过文件名前缀数字x找到该绝对offset 对应消息所在文件
2.offset-x为在文件中的相对偏移
3.通过index文件中记录的索引找到最近的消息的位置
4.从最近位置开始逐条寻找
26. 如果我指定了一个timestamp,Kafka怎么查找到对应的消息?
原理同上 但是时间的因为消息体中不带有时间戳 所以不精确
27. 聊一聊你对Kafka的Log Retention的理解
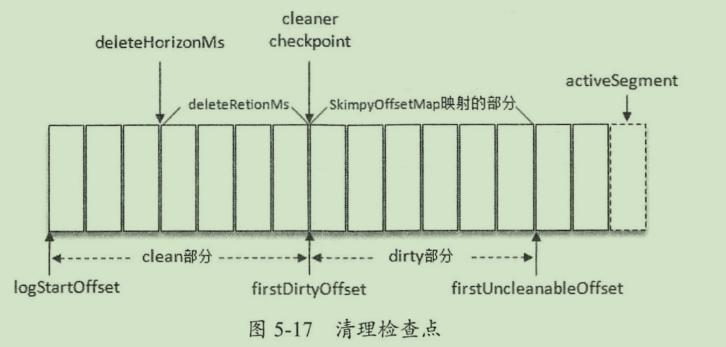
kafka留存策略包括 删除和压缩两种 删除: 根据时间和大小两个方式进行删除 大小是整个partition日志文件的大小 超过的会从老到新依次删除 时间指日志文件中的最大时间戳而非文件的最后修改时间 压缩: 相同key的value只保存一个 压缩过的是clean 未压缩的dirty 压缩之后的偏移量不连续 未压缩时连续
28. 聊一聊你对Kafka的Log Compaction的理解
kafka会将相同key的日志进行合并,只保留最后一个值。
29. 聊一聊你对Kafka底层存储的理解(页缓存、内核层、块层、设备层)
数据->内核层>虚拟文件系统->页缓存->具体文件系统->块层-(驱动程序)>设备层,
30. 聊一聊Kafka的延时操作的原理
在leader完成日志写入之后,会产生一个延时操作,用来监控同步操作是否超时,以及返回结果个客户端。
31. 聊一聊Kafka控制器的作用
一个集群只有一个broker,broker会管理集群里所有分区和副本的状态,broker的选举时看谁在zookeeper里最先注册/controller 节点。
32. 消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器)
33. Kafka中的幂等是怎么实现的
pid+序号实现,单个producer内幂等
33. Kafka中的事务是怎么实现的(这题我去面试6家被问4次,照着答案念也要念十几分钟,面试官简直凑不要脸。实在记不住的话…只要简历上不写精通Kafka一般不会问到,我简历上写的是“熟悉Kafka,了解RabbitMQ….”)
34. Kafka中有那些地方需要选举?这些地方的选举策略又有哪些?
分区leader 需要选取。broker需要选举
35. 失效副本是指什么?有那些应对措施?
副本时效是指因为某些原因,网络故障,宕机等,某些副本未达到isr的要求,同步跟不上leader 而成为失效副本。重启副本节点。剔除副本节点
36. 多副本下,各个副本中的HW和LEO的演变过程
37. 为什么Kafka不支持读写分离?
数据一致性问题,follower数据可能与leader 不同步
延时问题,同步消耗时间。
读写分配不均,可能造成热点问题。
38. Kafka在可靠性方面做了哪些改进?(HW, LeaderEpoch)
通过leaderepoch给每个leader 加上了版本号,startoffset 记录第一次同步的偏移量。通过对应的 防止数据丢失,与保持数据一致。
-ack
39. Kafka中怎么实现死信队列和重试队列?
40. Kafka中的延迟队列怎么实现(这题被问的比事务那题还要多!!!听说你会Kafka,那你说说延迟队列怎么实现?)
41. Kafka中怎么做消息审计?
42. Kafka中怎么做消息轨迹?
kafka monitor
43. Kafka中有那些配置参数比较有意思?聊一聊你的看法
44. Kafka中有那些命名比较有意思?聊一聊你的看法
45. Kafka有哪些指标需要着重关注?
生产者关注MessagesInPerSec、BytesOutPerSec、BytesInPerSec 消费者关注消费延迟Lag
46. 怎么计算Lag?(注意read_uncommitted和read_committed状态下的不同)
47. Kafka的那些设计让它有如此高的性能?
零拷贝,页缓存,顺序写
48. Kafka有什么优缺点?
49. 还用过什么同质类的其它产品,与Kafka相比有什么优缺点?
50. 为什么选择Kafka?
吞吐量高,大数据消息系统唯一选择。
51. 在使用Kafka的过程中遇到过什么困难?怎么解决的?
52. 怎么样才能确保Kafka极大程度上的可靠性?
53. 聊一聊你对Kafka生态的理解
confluent全家桶(connect/kafka stream/ksql/center/rest proxy等),开源监控管理工具kafka-manager,kmanager等